188 - Comparison of the Appropriate Use Criteria with Large Language Model Recommendations for Treatment of Pediatric Supracondylar Humerus Fractures with Vascular Injury
Medical Student Icahn School of Medicine at Mount Sinai New York, New York, United States
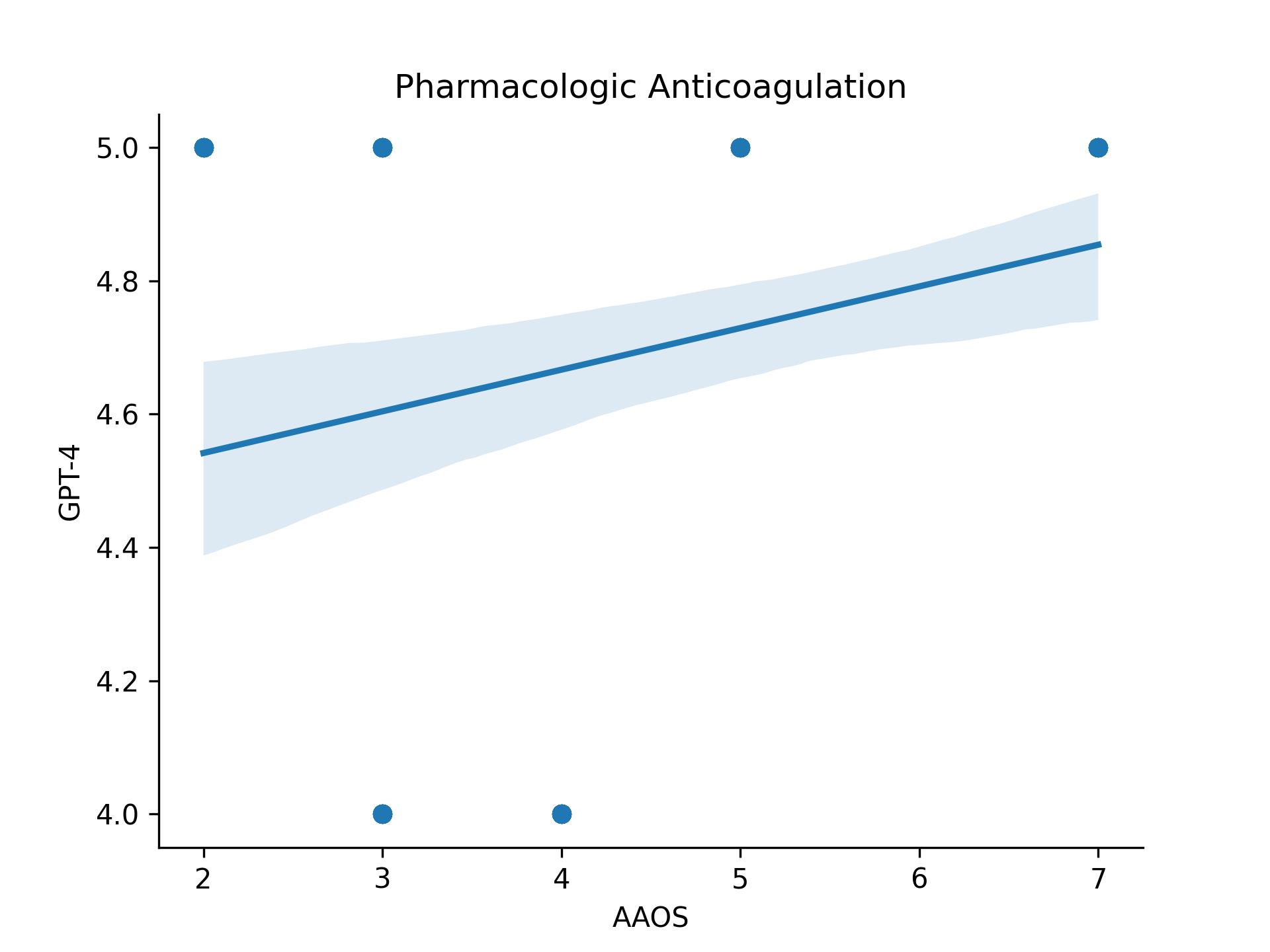
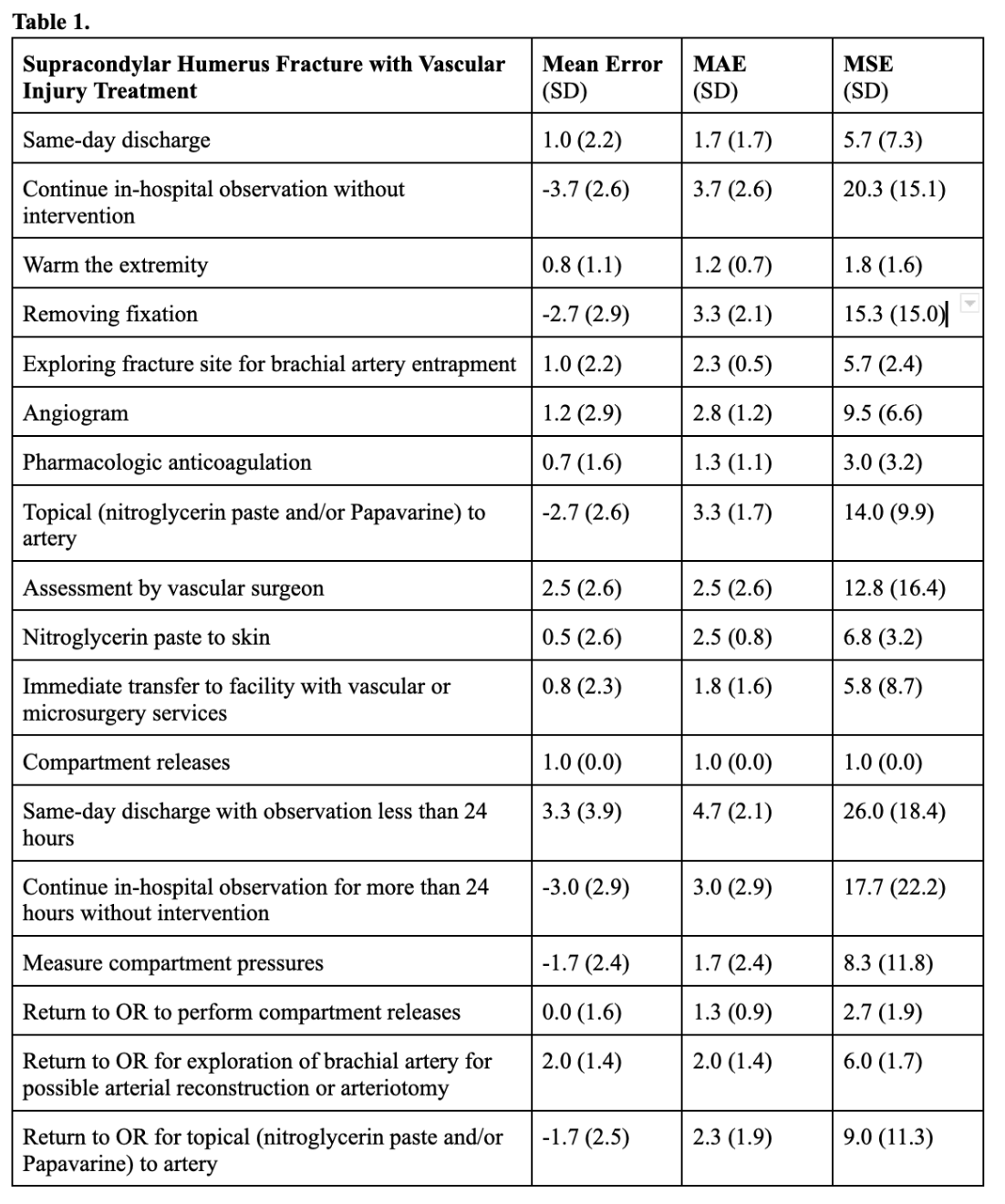
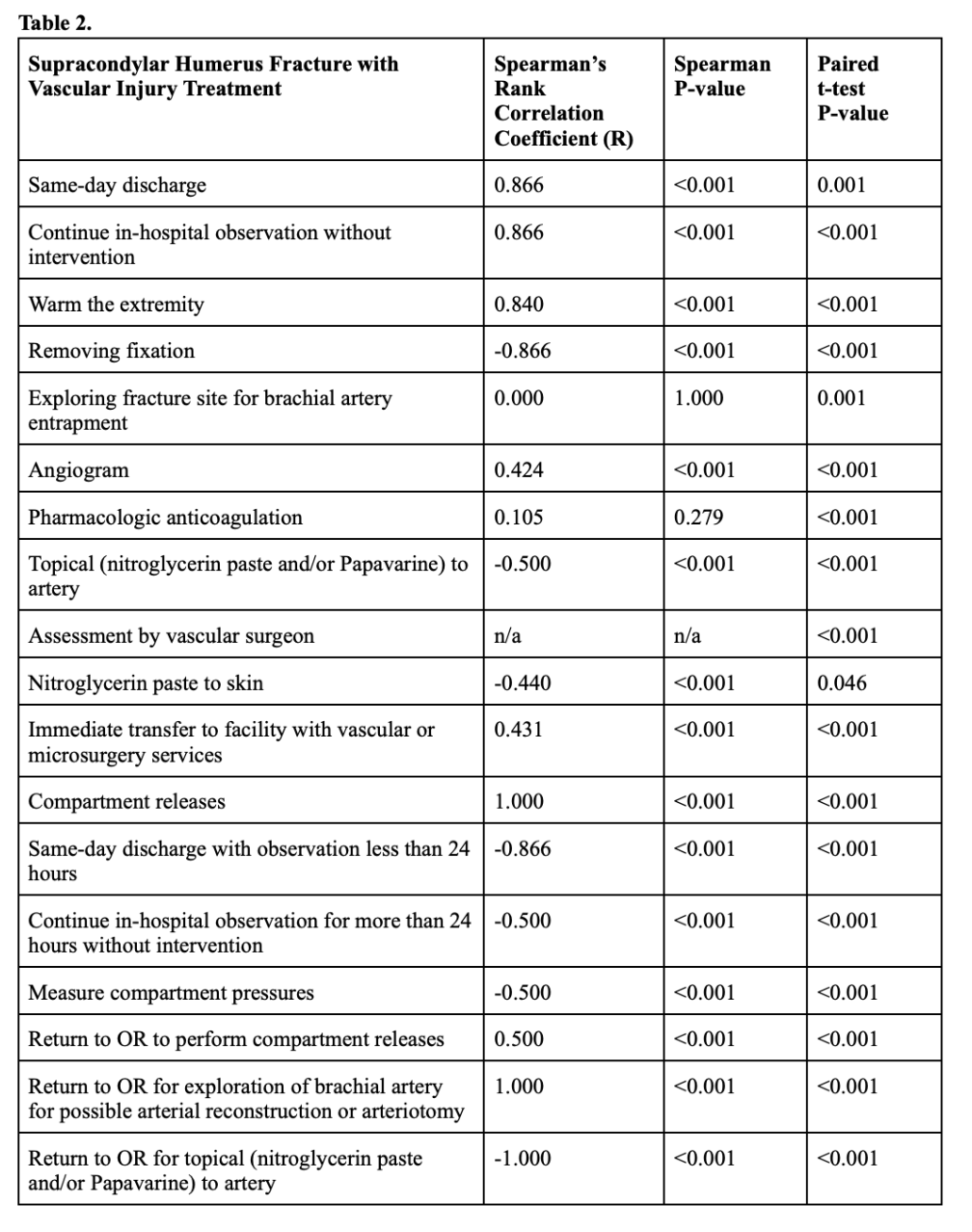
Background: Supracondylar humerus fractures (SCHF) account for 18% of pediatric fractures, with neovascular injury rates up to 49% and vascular compromise at 4-6%. Given the prevalence and complexity of these injuries, Chat Generative Pre-Trained Transformer (ChatGPT) may aid in recommending appropriate treatments. Objective: To assess ChatGPT-4.0’s clinical decision-making by comparing treatment appropriateness scores for SCHF with vascular injury with the American Academy of Orthopedic Surgeons (AAOS) Appropriate Use Criteria (AUC). Design/Methods: Appropriateness scores for 18 SCHF with vascular injury treatments were compared across AAOS AUC, the gold standard, and ChatGPT-4.0 in 6 scenarios. Scores were quantified on a scale of 1-9: 7-9=“Appropriate,” 4-6=“May be Appropriate,” and 1-3=“Rarely Appropriate.” Mean error, mean absolute error, and mean squared error were calculated. Spearman’s rank correlation coefficients and paired t-tests with alpha=0.05 evaluated non-equivalence. Results: The treatment options were assessed in 108 paired scores across 6 patient scenarios, each which produced a mean absolute error and mean squared error ≥1.0 (Table 1). Spearman correlation tests found significant positive correlations between AAOS and ChatGPT scores for same-day discharge (0.87, P< 0.001), continue in-hospital observation without intervention (0.87, P< 0.001), warm the extremity (0.84, P< 0.001), compartment releases (1.00, P< 0.001), and return to OR for exploration of brachial artery for possible arterial reconstruction or arteriotomy (1.00, P< 0.001) and significant negative correlations for removing fixation (-0.87, P< 0.001), same-day discharge with observation less than 24 hours (-0.87, P< 0.001), and return to OR for topical (nitroglycerin paste and/or Papavarine) to artery (-1.00, P< 0.001). The paired t-test found significant differences for all treatments; other than same-day discharge (P=0.001), exploring fracture site for brachial artery entrapment (P=0.001), and nitroglycerin paste to skin (P=0.046), all options yielded P< 0.001 (Table 2). Scatterplots revealed ChatGPT overestimated appropriateness in 11 treatments, underestimated in 6, and found comparable scores for return to OR to perform compartment releases (Figure 1).
Conclusion(s): Comparing ChatGPT-4.0’s appropriateness scores to those of AAOS AUC revealed non-equivalence for all treatment options. Large language models such as ChatGPT can aid in synthesizing key literature and guiding clinical decisions for pediatric injuries but need improvement to accurately assess treatments for pediatric SCHF with vascular injury.

 photo")