Medical Student Icahn School of Medicine at Mount Sinai New York, New York, United States
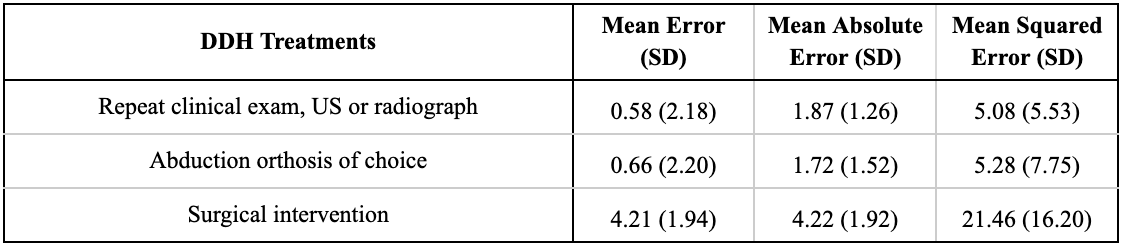
Background: Developmental dysplasia of the hip (DDH) is one of the most common pediatric orthopedic hip conditions and is characterized by atypical hip development leading to dysplasia, subluxation, and possible dislocation. As AI-driven tools such as ChatGPT continue to evolve, they may play an increasing role in guiding optimal care and may be useful in informing appropriate DDH management. Objective: We aimed to evaluate the accuracy of ChatGPT-4.0 by comparing its appropriateness scores for DDH treatment courses with the American Academy of Orthopedic Surgeons (AAOS) Appropriate Use Criteria (AUC). Design/Methods: Appropriateness scores provided by AAOS for DDH treatment options based on various patient factors were compared to ChatGPT-4.0’s appropriateness score for each possible patient profile. The AUC delineated patient profiles using age, risk factors (breech presentation, family history, history of improper swaddling or clinical instability), physical exam findings, ultrasound findings, and International Hip Dysplasia Institute (IHDI) AP Pelvis Radiograph Grade. The treatments assessed were repeat clinical exam and imaging, abduction orthosis, and surgical intervention. The AUC rated treatment appropriateness for each option from 1 to 9: 7-9 ("Appropriate"), 4-6 ("May Be Appropriate"), 1-3 ("Rarely Appropriate"). Mean error, mean absolute error, and mean squared error were calculated. Spearman’s rank correlation coefficients and paired t-tests were used to determine statistical significance with alpha=0.05. Results: 720 patient profiles were evaluated among 3 treatment options for a total of 2,160 paired scores. Comparing ChatGPT with AUC scores, the mean squared error was 5.08±5.53 for repeat clinical exam and imaging, 5.28±7.75 for abduction orthosis, and 21.46±16.20 for surgical intervention. There was a significant very weak correlation between AUC and ChatGPT-4.0 scores for repeating a clinical exam and imaging (R=0.11, p=0.006), weak correlation for abduction orthosis (R=0.25, p< 0.001), and moderate correlation for surgical intervention (R=0.45, p< 0.001). The paired t-test revealed non-equivalence between scores for all 3 treatment methods (p < 0.001).
Conclusion(s): At this time, ChatGPT-4.0 is not a reliable resource relative to the AUC when determining the appropriateness of DDH treatments. While large language models hold promise as valuable tools in clinical decision-making, significant differences between scores indicate that ChatGPT-4.0 is currently ill-equipped to quickly and accurately assess the efficacy of clinical decisions surrounding DDH management and requires further validation.

.jpg "Jiwoo Park, BA (she/her/hers) photo")
.png)
.png)