Session: Neo-Perinatal Health Care Delivery 4: Epidemiology/Health Services Research
280 - Very Low Birthweight Infant profiling in the large, heterogenous, non-population NEOCOSUR neonatal network. An unsupervised machine learning approach.
Neonatologist Hospital Universitario Austral Pilar, Buenos Aires, Argentina
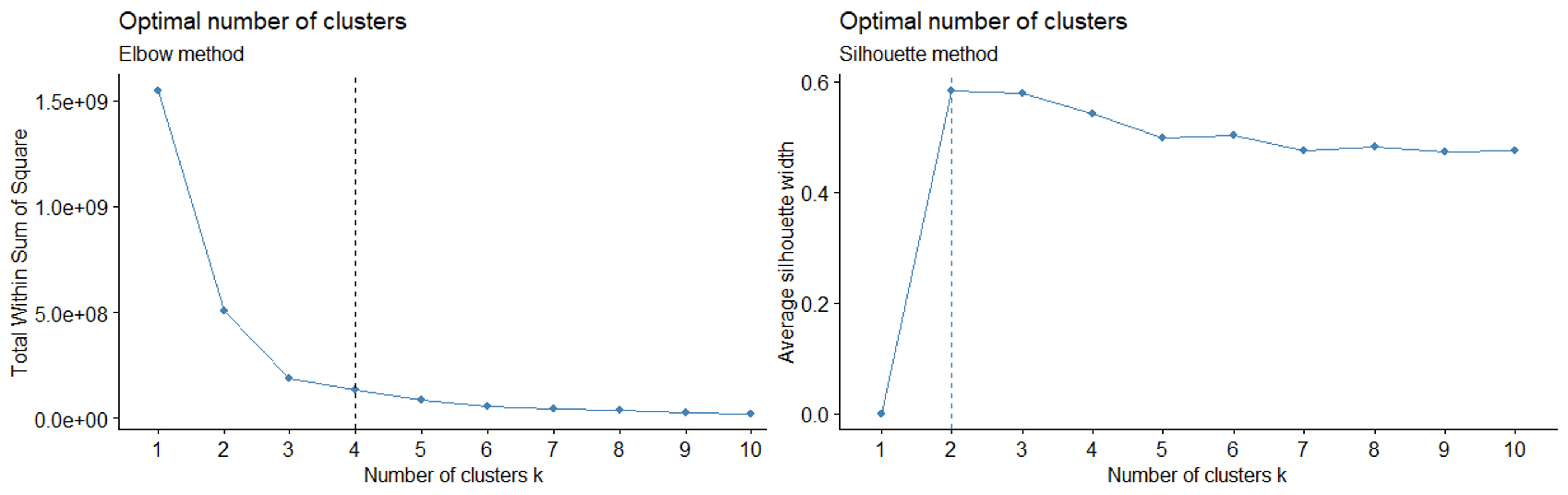
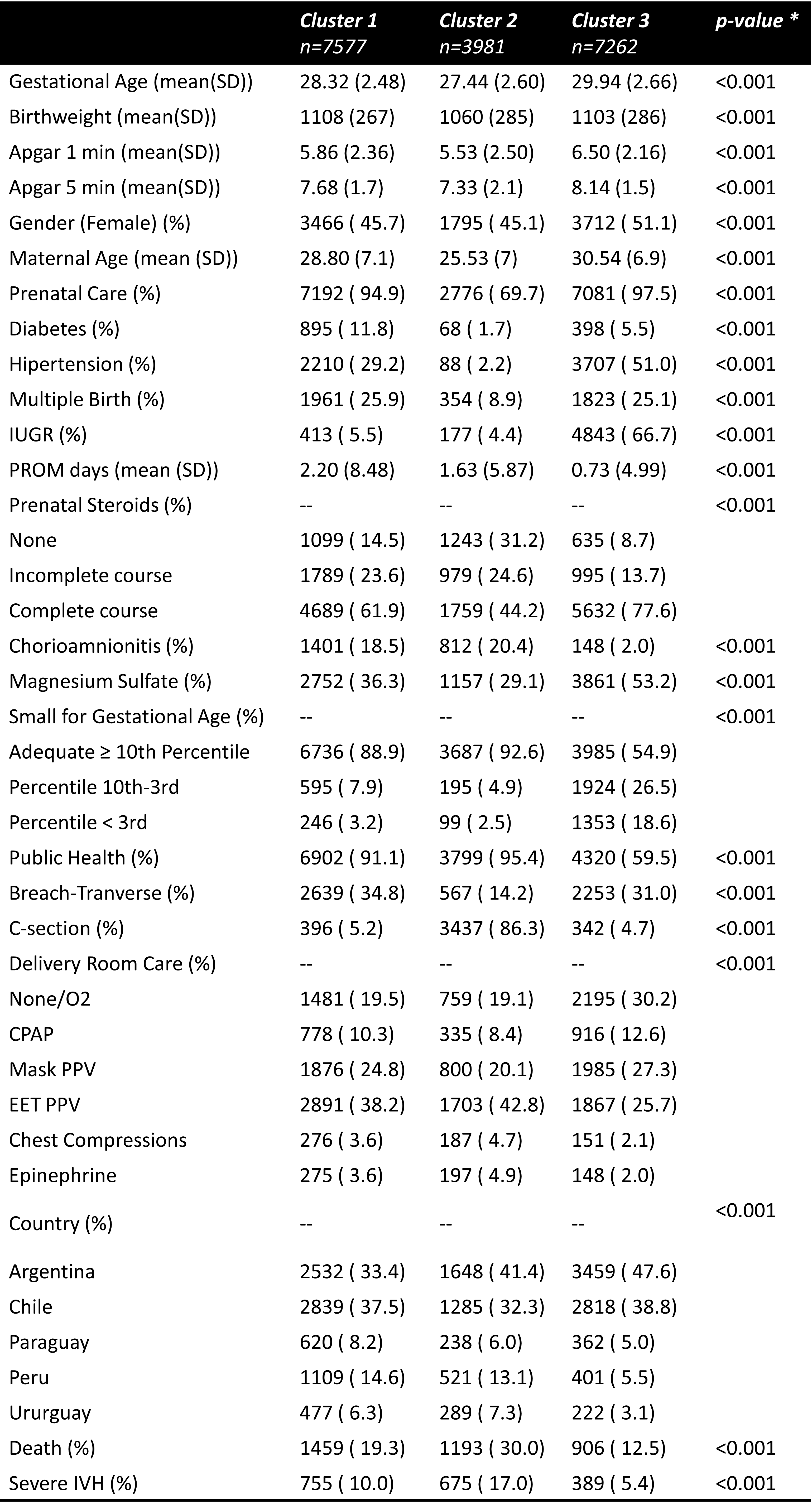
Background: Given its non-population-based and non-probabilistic sampling, the Very Low Birthweight NEOCOSUR neonatal network from Argentina, Chile, Paraguay, Perú and Uruguay, exhibits an asymmetric structure. Previous studies of our group have shown a significant clustering effect of participant centers that can be attributed to known and latent perinatal exposures. Using multilevel regression with centers as a secondary level, improves estimation precision, however, other exposures can create clustering effects and if considered may also improve outcomes prediction. Objective: To uncover hidden exposure patterns among VLBW infants in the NEOCOSUR neonatal network using unsupervised machine learning algorithms applied to a comprehensive set of perinatal exposures including network centers. Design/Methods: After exclusion of major congenital malformation observations and centers with less than 3 years of registers, imputation of missing values, and scaling of continuous variables, we analyzed a dataset of 18,820 VLBW infants from 31 centers across 5 countries, born between 2012 and 2022. A Hierarchical Agglomerative Clustering algorithm with Gower Distance metric and Ward's Linkage method was applied to identify clusters within the dataset. Following clustering, we conducted both between and within-cluster analyses to evaluate the impact of exposure variables on VLBW infant patterns through Fisher exact test, ANOVA with Tukey correction and multiple generalized linear models. Results: Based on Dunn’s index and both, Elbow and Silhouette metrics, the dataset was separated into 3 clusters. Figures 1 & 2 shows those metrics, the dendrogram plot and the list of variables involved on clustering. Fig 3 shows between-clusters analysis with significant differences including perinatal exposures, centers, and countries. Additionally, although unlabeled on clustering process, mortality, and morbidities outcomes showed significant differences between the 3 clusters. Whitin each cluster, backwards selected variables to predict mortality on logistic regression models were different between clusters (data not shown)
Conclusion(s): Clustering techniques may contribute to detecting unknown patterns of infants in large networks based on multiple perinatal determinants instead of classical Gestational Age and/or Birthweight strata. This better characterization and understanding of groups may enhance and direct complex quality improvement actions to those infants, centers, or even countries as needed and, furthermore, to consider this hierarchical structure for predictive regression models and risk scoring development.

 photo")
.png)