System architect and principal data scientist - medical NLP (Contract) Boston Children's Hospital Bergisch Gladbach, Nordrhein-Westfalen, Germany
Background: Semantic search (returns content matching the meaning of a query rather than word matching), is a critical element in clinical information retrieval. Large Language Models (LLMs) have emerged as best practice for implementing semantic search in this context. Objective: To evaluate pre-trained medical LLMs for semantic search on presence of fever in pediatric clinical documentation. Design/Methods: We annotated 30 sentences from random pediatric ED documentation, labeling notes addressing presence or absence of fever (15 sentences in each group, see Table 1). We chose fever for its high prevalence in ED documentation as well as high variability in documentation (narrative, numeric, different scales etc.) Sentences were selected from a wide range of medical notes, ensuring diversity among patients.
We first tested the capability of 8 common medical LLMs to generate sentence embeddings that exhibit high semantic similarity within each category but lower semantic similarity between the two groups (table 2). Thus, able to identify patients with fever while omitting those without fever. For each LLM, we computed word embeddings for all annotated sentences and employed cosine distance (a metric for measuring similarity). We then employed the Mann–Whitney U test to evaluate whether the internal cosine similarity within each group (Fever and then NoFever groups) surpasses the similarity between sentences across groups.
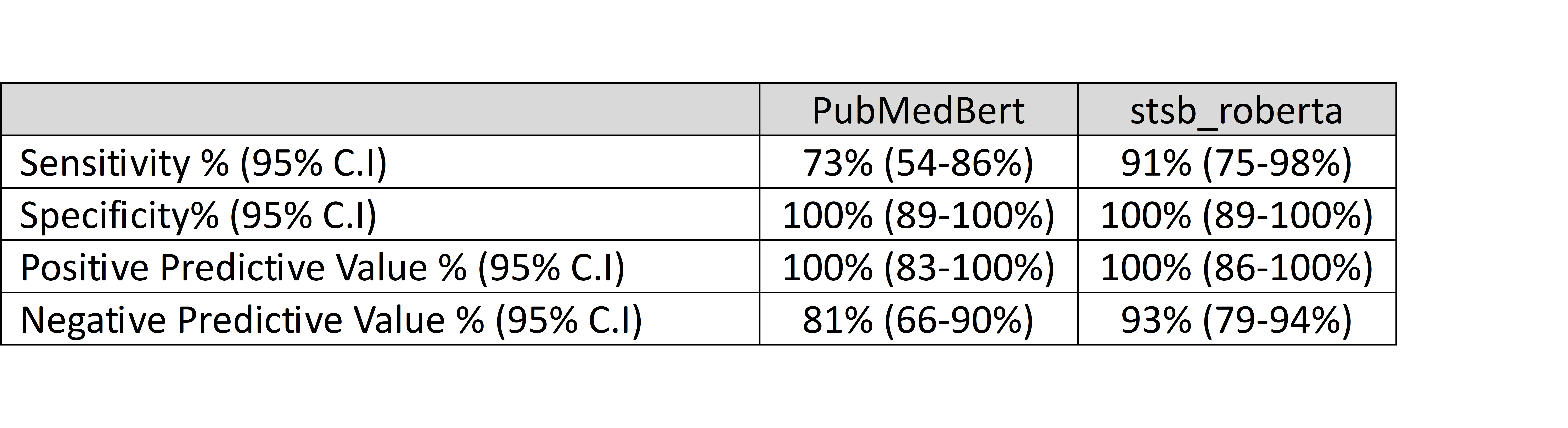
Finally, we validated two of the models on a manually reviewed external set of ED notes. This validation set consisted of 71 notes that were identified by both models as part of their respective top 100 documents for Fever and for NoFever. Results: The Mann–Whitney U test results (Table 2) found differences in the performance of the eight medical Language Models (LLMs). These results confirm the distinctions in the word embeddings generated by different LLMs when tested on pediatric narratives. Table 3 presents the performance metrics of two searches, using two distinct LLMs, ranked 1st and 6th in the first test, on external validation data. The LLM that exhibited superior performance in the initial assessment, conducted exclusively on the sentences comprising the semantic search query, likewise demonstrated better efficacy on an external dataset of ED notes.
Conclusion(s): There is large variation in the performance of different medical LLMs in semantic search. We therefore recommend a systematic LLM selection for each specific medical information retrieval query. Our method offers a fast way to test different LLMs, providing results that mirror the time-consuming manual review for validation.