MD University Health System Children's Health san anotonio, Texas, United States
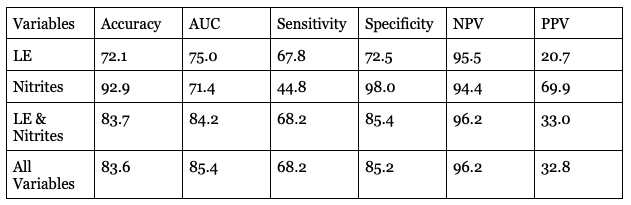
Background: Diagnosing urinary tract infections (UTIs) presents a unique challenge for healthcare providers. The subjective nature of urinalysis interpretation often results in a discrepancy, where only 44% of pediatric patients initially diagnosed with UTIs are subsequently confirmed to have UTIs based on culture testing. Objective: To develop a machine learning (ML) algorithm to enhance UTI diagnosis accuracy, ultimately reducing unnecessary antibiotic prescriptions and their associated side effects. Design/Methods: We conducted a retrospective analysis involving pediatric patients ( < 21 years old) who underwent dipstick point-of-care (POC) urinalysis or complete urinalysis (CUA) testing from 2017 to 2019 at a large referral center in central Texas. The primary outcome was UTI, defined as a positive urine culture (catheter specimen ≥50,000 CFU, clean catch ≥100,000 CFU). Specimens that indicated contamination were defined as a negative urine culture. A training set (80% random sample) using routinely available demographic information and POC or CUA data were used as predictors. Five ML-based models were built (e.g., logistic regression, decision tree, random forest, XGBoost, and neural networks). In the test set, (20% holdout sample), we measured the model’s predictive performance by computing accuracy, sensitivity, specificity, area under the curve, as well as negative and positive predictive value. Given the low prevalence of UTI, we used synthetic minority oversampling to balance the data. Results: Of 20,724 (POC=5,667+CUA=15,057) patient encounters, there were 16,365 females and the overall median age of 12 years with a UTI prevalence sex ratio of 6.5% in males and 11.8% in females. The range of the area under the curve for the five ML POC and CUA models was between 71.7%-88.5% and 70.2%-85.4% respectively. The best ML model for the POC data was a neural network which yielded a sensitivity and specificity of 76.1% and 84.4%. Meanwhile the best ML model in the CUA dataset was logistic regression with a sensitivity of 68.2% and specificity of 85.2%. Variables used to build the models included age of the child, lab turnaround time (i.e., time from urine collection to laboratory delivery) and the following urine variables: leukocyte esterase, nitrites, blood and specific gravity.
Conclusion(s): Leveraging ML provides an objective approach to interpreting urinalysis, offering valuable assistance to clinicians in enhancing the accuracy of UTI diagnosis. Currently, we are conducting a prospective study to validate the algorithm's performance in a different healthcare system.


.png)